Pada hari sebelumnya telah dibahas tentang
konsep dari regresi logistik biner. Sesuai dengan janji penulis akan dibahas
tutorial regresi logistik biner dengan SPSS. (kayak pemilu aja ya.:p). Untuk contoh kasus kali ini, terinspirasi dari tugas kelompok perkuliahan yang diambil dari tugas kakak tingkat. bisa dibilang copas lah ya. tapi, jangan dilihat dari copasnya. tapi lihat dari niatnya dan keinginan untuk saling berbagi semoga dapat membantu mengerjakan tugas, skripsi, tesis atau bahkan disertasi.
Contoh Kasus Analisis Regresi Logistik biner:
Dilakukan simulasi untuk melihat pengaruh antara variabel profitabilitas, kompleksitas perusahaan, opini auditor, likuiditas dan ukuran perusahaan terhadap ketepatan penyampaian laporan keuangan tahunan perusahaan. Profitabilitas diukur dengan ROA; variabel kompleksitas terdiri atas 2 kategorik yaitu diberi angka 2 jika mempunyai anak perusahaan dan 1 jika perusahaan tidak mempunyai anak perusahaan; opini auditor diukur dengan 2 jika mendapatkan opini wajar tanpa pengecualian dan 1 untuk opini yang lain; likuiditas diukur dengan Current Ratio; dan ukuran perusahaan diukur dengan logaritma natural market value. Variabel terikatnya adalah ketepatan penyampaian laporan keuangan, dengan kode 1 untuk perusahaan yang tepat waktu dan 0 untuk perusahaan yang terlambat.
Data yang digunakan dalam penelitian ini tidak ditampilkan mungkin kalau teman ingin mencoba juga bisa didownload dibagian bawah nanti ya. dalam tutorial ini menggunakan
SPSS 20.Langsung saja ya dengan langkah-langkahnya.
Langkah-langkah dalam pengujian analisis regresi logistik
- Pada posisi file telah terbuka, maka akan terlihat pada layar data tentang ketepatan penyampaian laporan keuangan perusahaan dengan sejumlah variabel-variabelnya. Untuk menganalisis, langkah awalnya adalah pilih menu Analyze, kemudian pilih Regression dan Binary Logistic. Maka akan muncul tampilan seperti di bawah ini.
- Masukan variabel yang berfungsi sebagai variabel tak bebas dari box variabel ke kolom dependent, dan masukan semua varibel bebas pada kotak Covariate. Untuk Method, pilih Enter. Sebenarnya bisa dipilih metode apa saja karena model yang terbentuk akan sama (dalam artian penduga-penduga parameternya akan memiliki nilai-nilai yang sama). Akan tetapi, khusus metode Enter, harus dilakukan proses dua kali. Pertama, data di run dengan semua variabel untuk mengetahui variabel mana yang signifikan, setelah itu di run lagi dengan menggunakan variabel yang signifikan itu. Model yang terbentuk akan sama dengan model yang diperoleh dengan metode lain.
- Klik Categorical, masukkan semua variabel bebas yang berbentuk kategori pada kotak covariate ke dalam kotak categorical covariates, biarkan contras pada default indicator. Untuk reference kategori pilih bagian kategori yang akan dipakai sebagai referensi atau pembanding yang akan digunakan dalam interpretasi odds ratio. Dapat menggunakan kategori akhir (last) atau kategori pertama (first). Dalam penelitian ini digunakan kategori akhir (last). Kemudian klik Continue. Setelah itu pilih menu option, centang iteration history untuk dapat mengetahui proses iterasi yang telah berlangsung.
- Selain itu, akan ditemukan "Classification cut off", yang pada kondisi default sudah diisi dengan 0.5. Nilai ini disebut dengan the cut value atau prior probability, peluang suatu observasi untuk masuk ke salah satu kelompok sebelum karakteristik variabel penjelasnya diketahui. Jika kita tidak mempunyai informasi tambahan tentang data kita, maka kita bisa menggunakan default. Misalnya pada penelitian ini, sebelumnya tidak pernah dilakukan penelitian apakah ukuran perusahaan condong pada satu sisi. dengan alasan ini, dapat digunakan classification cutoff sebesar 0,5. Namun, misalnya pada ada penelitian lain yang telah meneliti maka bisa dinaikkan/diturunkan classification cutoff sesuai hasil penelitian. Dalam penelitian ini semua variabel numerik dalam default 0,5. Abaikan bagain yang lain, klik continue.
- Abaikan bagian yang lain, dan tekan OK maka akan keluar output dari Regresi Logistik.
Intrepretasi Hasil analisis regresi logistik
Setelah keluar
output dari hasil running data di SPSS maka diperoleh hasil analisis sebagai berikut :
Identifikasi Data yang Hilang
Pada tabel di atas, dapat dilihat tidak ada data yang hilang (
missing cases).
Pemberian kode variabel respon oleh SPSS
Menurut pengkodean SPSS, yang termasuk kategori sukses adalah penyampaian laporan keuangan tahunan yang tepat.
Pemberian kode untuk variabel penjelas yang kategorik
Pengkodean variabel penjelas hanya dilakukan untuk variabel penjelas yang kategorik karena akan dibentuk dummy variabel. Penelitian ini menggunakan dua variabel penjelas yang kategorik yaitu variabel Opini dan variabel Kompleksitas. Untuk variabel
opini, nantinya yang akan digunakan sebagai
reference code (kode pembanding) adalah Wajar Tanpa Pengecualian (lihat pada tabel di atas bagian parameter codings yang berkode nol). Sementara untuk variabel
Kompleksitas, yang menjadi kode pembanding adalah Punya anak perusahaan. Kode pembanding ini akan digunakan untuk interpretasi Odds Ratio.
Uji Signifikansi Model
Dari hasil SPSS dapat digunakan tabel “
Omnibus Tests of Model Coefficients” untuk melihat hasil pengujian secara simultan pengaruh variabel bebas ini.
Berdasarkan tabel di atas diperoleh nilai Sig.Model sebesar 0.000. Karena nilai ini
lebih kecil dari 5% maka kita menolak Ho pada tingkat signifikansi 5% sehingga disimpulkan bahwa variabel bebas yang digunakan, secara bersama-sama berpengaruh terhadap ketepatan penyampaian laporan keuangan suatu perusahaan. Atau minimal ada satu variabel bebas yang berpengaruh.
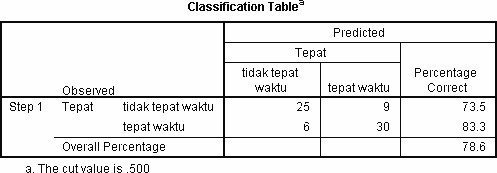
Persentase Ketepatan Klasifikasi (Percentage Correct)
Persentase ketepatan model dalam mengkasifikasikan observasi adalah 78.6 persen. Artinya dari 70 observasi, ada 55 observasi yang tepat pengklasifikasiannya oleh model regresi logistik. Jumlah observasi yang tepat pengklasifikasiannya dapat dilihat pada diagonal utama.
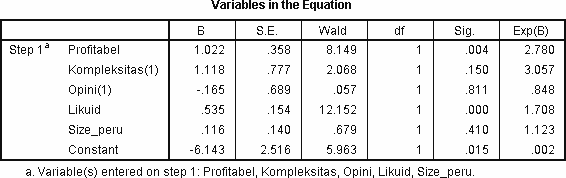
Uji Parsial dan Pembentukan Model
Pada uji diharapkan Ho akan ditolak sehingga variabel yang sedang diuji masuk ke dalam model. Dengan bantuan tabel “Variables in The Equation” dapat dilihat variabel mana saja yang berpengaruh signifikan sehingga bisa dimasukkan ke model. Jika nilai sig.<a maka Ho ditolak.
Berdasarkan hasil di atas diketahui bahwa terdapat 2 variabel bebas yang signifikan berpengaruh terhadap ketepatan penyampaian laporan keuangan perusahaan karena masing-masing variabel tersebut memiliki nilai signifikansi yang lebih kecil dari a=5%. Variabel-variabel tersebut adalah Profitabilitas (Sig.=0.004)dan Likuiditas (Sig.=0.000). Model yang terbentuk adalah :
Dimana :
X_1i = Profitabilitas
X_2i= Likuiditas
i=1,2,…,n
7.Interpretasi Odds Ratio
Nilai Odds ratio ini juga disediakan oleh tabel “
Variables in The Equation” pada kolom Exp(B) :
Berdasarkan hasil di atas kita dapat menginterpretasikan Odds ratio sebagai berikut :
- Jika jumlah profitabilitas perusahaan bertambah 1 unit maka kecendrungan perusahaan tersebut untuk tepat waktu menyampaikan laporan keuangan menjadi 2.780 kali lipat.
- Sebuah perusahaan yang tidak mempunyai anak perusahaan akan memiliki kecenderungan untuk menyampaikan laporan keuangan secara tepat waktu sebesar 3.057 kali dibanding perusahaan yang memiliki anak perusahaan (merujuk pada reference code).
- Perusahaan dengan opini auditor adalah opini lain cenderung 0.848 kali (lebih rendah) untuk tepat waktu dalam menyampaikan laporan keuangan dibanding dengan perusahaan yang Wajar tanpa Pengecualian.
- Jika Current ratio pada likuiditas bertambah 1 persen maka perusahaan akan cenderung 1.708 kali untuk tepat waktu menyampaikan laporan keuangannya.
- Ketika ukuran perusahaan bertambah 1 unit maka perusahaan tersebut cenderung 1.123 kali untuk tepat waktu dalam menyampaikan laporan keuangannya.
Buat yang ingin mencoba silahkan download filenya dibawah ini:
tutorial reglog biner (SPSS 20)
 1. Buka Microsoft Excel 2007 tentunya.
1. Buka Microsoft Excel 2007 tentunya.